The 'Now' namespace for RSS
Note: The namespace has it's own domain and is on GitHub.
Just before bed last night I had a flood of inspiration following on from the /updates page and Bix's idea of followable /now pages. With RSS being my preferred method of distribution I thought about how this could be achieved.
Introducing the 'Now' namespace for RSS
After initially reading Robin Sloan's proposal for the Spring '83 protocol 1 I suggested that RSS feeds could have "a 'block' that shows under certain circumstances". This, combined with the new 'updates' view for /reader, gave me the idea of creating a namespace (itself inspired by the /now page) to specify the elements required for such a block.
The namespace is documented on it's own site here or on GitHub (feel free to comment by creating an issue). The (channel level) elements defined are:
-
now:title – (optional) a title for the update
-
now:link – (optional) - the link to a /now page or other source of updates
-
now:content – (required) the update content itself, plain text or CDATA block
-
now:markdown – (optional) markdown version of the update content
-
now:timestamp – (optional) the time of the update
The source of update for the 'block' can be anything, not just a /now page; I am using the contents of /now as a proof of concept. When the RSS feed is built it pulls in the contents of the now page from the database.
As an example, the information in my feed is consumed in /updates after having modified the feed parser library to support the namespace elements. It looks as below:
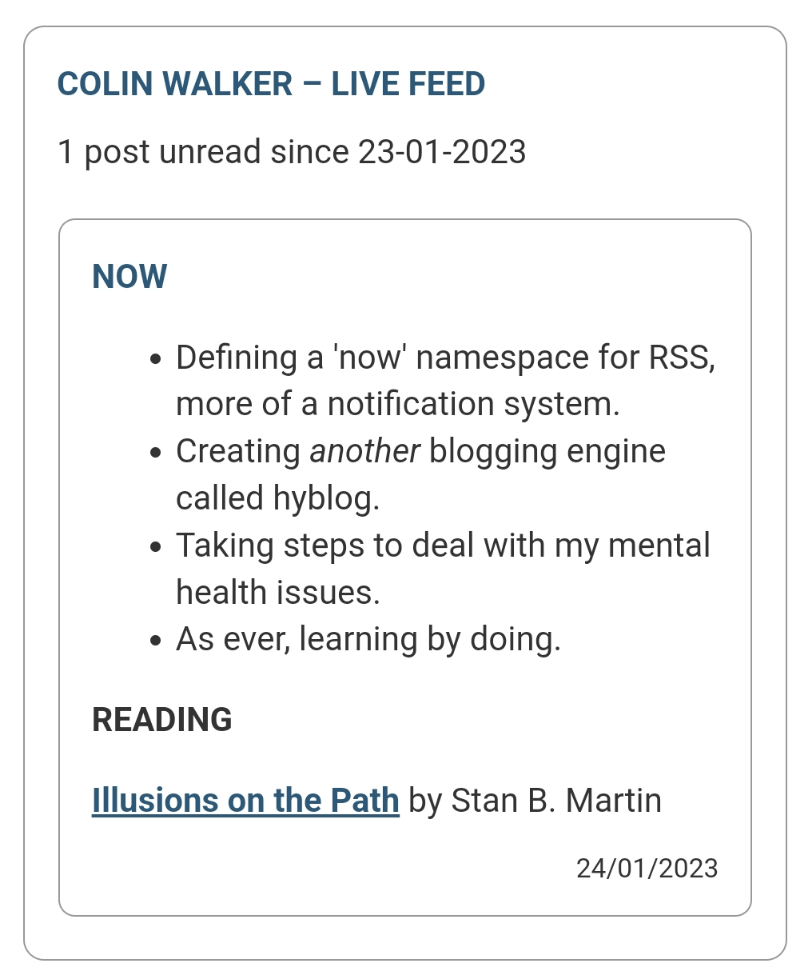
Comments? Suggestions? Is this a viable means of making 'now-like' updates shareable and followable?
-
where updates would be shared as small 'boards' and a resulting collection of boards would look like a magazine rack or the small ads from a newspaper ↩
An initial version of the 'feed updates' page is live.
(See this post for the background.)
It's nice and simple, just listing those sites with unread updates, how many and since when. A 'mark as read' check mark is shown next to each when logged in.

This is, obviously, only intended for me as it reflects my unread status in /reader. It's an experiment to see how it affects my reading behaviour.
An extra option has been added to /admin to choose the default view of /reader so that I can switch between this and the standard 'items' view. This doesn't affect the view when not logged in.
Back in May I started looking at making feed fetching in /reader more efficient and explored the options for running PHP processes in parallel.
Unfortunately, the common methods (async, pthreads, parallel) are not supported by my hosting.
The library I'm using to consume feeds uses cURL (if installed, file_get_contents() if not) to grab the feed contents but doing this repeatedly for multiple feeds takes time – with the 29 feeds I had it was taking around 18 seconds to do a full refresh.
I recently came across 'cURL multi' 1 which allows the processing of multiple cURL handles asynchronously so wondered if I could make that work here. On Wednesday evening, as is my way, I started overcomplicating matters thinking I was going to have to rewrite the library. Tired and confused I went to bed wondering how I was going to achieve this.
Yesterday, however, I realised that, rather than need to rewrite things, I could just make a couple of the private functions public and call the library one stage further in. Instead of the library making single cURL requests, I could do the multi requests first and pass the results to the (now public) later functions.
The upshot is that a full refresh now takes less than three seconds for 31 feeds – a sixth of the time it was previously taking! As I add more feeds the time savings will only get larger.
-
I'm still learning my way around PHP. I haven't got to classes yet, using them confuses my old brain. ↩
I keep going back to the thought that "the most focus you'll ever have" on something is when it first grabs you.
I've had a number of items left as unread in Reader, a number of notes left unfinished, a number of tabs left open, all just waiting for me to return to them and write something.
Two years ago, Drew Coffman wrote that notes can be a graveyard for your thoughts, written down then lost. I remarked that it felt my blog could be like this: "that I'm not doing enough with what I've got, making do instead of making strides."
If that is the case, if it is a graveyard, then I want to speak to the dead, build on their ideas. (And by 'the dead' I mean past instances of me who thought something was worth linking to or writing about.) That's why I've made all the recent changes to the site. Reader, Start, it's all about extending blogging, getting more from it, hopefully doing more with it by creating pathways through my thoughts over time.
Tom Critchlow wrote about increasing the surface area of blogging; he was talking about blogging as a whole but it can equally apply to a single blog. Creating a larger surface area allows for more scope, more references, more links, more connections – with some work and a bit of luck that leads to more ideas. Critchlow wrote:
"I think there's something quietly radical about making your feed reader open by default. It increases the surface area of RSS so others can discover content more easily. It makes blogging more visible."
That's true but, in a setup like mine, it also allows for easier consumption and reuse.
The desire to turn the blog into a database, rather than just be held in one, has been long standing, five years at least. My interest was, therefore, piqued when CJ Eller quoted Justin Murphy's post Personal Knowledge Management is Bullshit. Murphy argues that having an ever expanding dataset is "oppressive not impressive. It's not useful, and it's not illuminating."
"Individuals blessed with high degrees of industriousness and orderliness will build sophisticated media diets, note-taking systems, and automated archiving pipelines much more effectively than those less blessed with these traits."
Then they try to sell these systems to the rest of us.
I am definitely more of the latter, the 'less blessed' and always have been; organisation has never been a strength. To that end, I've always been a bad curator. Start is an attempt at improving things, taking them out of my hands to a degree, with a minimum of effort.
It seems a waste to have years of material, of my personal history, sat there for its own sake rather than be able to take advantage of the potential held within. But Eller likens PKM to a garbage heap, "a perpetually expanding web of hyperlinked notes" asking how we can prevent one from developing and save ourselves from such a fate.
Maybe the answer is simply to be selective.
For various reasons, I have been very bad at feeding the machine, very few posts have been marked with labels that would place them within my system. Maybe that's a good thing. By being slow to add items I am preventing an unwieldy build up. I originally intended to throw all sorts in but find that something really has to resonate before it gets labelled.
I also feel that integration is key. Having tried a wiki-like system in the Garden I decided it was better to have any form of PKM as integral to the blog, directly fed by it rather than as a separate repository. Thoughts and ideas are posted once to the blog, why duplicate the effort? I don't want it to be what most would consider a traditional PKM system. Yes, there are bi-directional links in some cases and, between posts, I have the ability to indicate these links, but there are few. Instead, I mainly rely on internal webmentions to indicate related posts. Start deals more with mini-hierarchies originating from individual starting points, threads rather than a web.
Perhaps the blog is finally ready to be the "digital public commonplace book" or thought space alluded to by Chris Aldrich almost two and a half years ago.
Past, present and future me are in a far better position to communicate across the years than ever without having to shoulder too heavy a burden, or continually sort through (and possibly dispose of) a garbage heap. The blog exists in its own right, and will continue to do so for years to come. Everything needed is held within and I now have a way to unlock it.
What could be easier than that?
My indie, integrated feed reader
For a few years now, it has been a goal (or more of a dream) to build my own feed reader which integrates directly with the blog making it easy to perform indieweb actions such as likes and replies.
I started building a WordPress plugin back in 2018 but quickly abandoned it as I didn't have the coding skills necessary at the time.
Today I am officially unveiling /reader, my new indie, integrated feed reader.

Before getting to the details I wanted to say that this has been made possible thanks to this RSS & Atom parser by David Grudl, it took a lot of the grunt work out of the equation meaning I could focus on the important bits.
Down to business
Reader adopts the visual style from the blog and my notes page displaying items as 'cards' in a river of news – oldest first. It can show all items, per feed or the last 24 hours.
New feeds can be added individually or imported from an (uploaded) OPML file. When added, the posts for that feed will be automatically pulled in. A cron job polls for new items every 30 minutes checking the last time the feed was updated to see if it needs to grab new items. That date is then written to the database for the next time it checks.
I'm currently storing a rolling three months of items but may reduce this to keep the table size down. When polling for posts it compares the timestamp (e.g. pubDate or updated) against 'now minus three months' and ignores anything older. New items are pulled into the database and those older than three months are deleted.
I can trigger a manual update at any time via a 'refresh' icon which triggers an async action to poll feeds in the background. The feed list (which slides out from the left) shows which feeds have unread items.
Indie and Integrated
So, why go to all the trouble of building my own feed reader? The main reason is integration with the blog. It's also another aspect of my online life that I can bring into my own control.

In addition to 'mark as read' each 'card' has actions which allow me to post directly to the blog and send webmentions. I can like, reply to or bookmark a post and the relevant Webmention will be sent.
Tapping each of these actions brings up a form populated with the post URL and the 'content filter' to add the required markup. I can then add some comments or my reply and post that straight to the blog.
I can 'mark all as read' which does as it suggests unless viewing a single feed when only items for that feed are marked.
Public/Private
The /reader page is publicly available but all admin and post actions are gated behind login checks. Anyone is welcome to come and have a look at what feeds are listed – the posts visible will reflect my read/unread status.
I am considering adding the ability for anyone to download an OPML export of the feeds list should they want. I might also add an option to 'suggest a feed' where visitors can let me know of a site they think I should be subscribed to.
v1.0
This is a version 1.0 feature that likely has bugs and needs tidying up or refining so it will likely change as I use it more and come up against issues or frustrations. I've already thought of one thing I want to add while typing this.
It doesn't support JSON feed but someone submitted a PR to include this in the library so I may look at implementing that in future.
Here's a short video of /reader in action.
